Terminologi Machine Learning
Dalam pembuatan model machine learning tentunya dibutuhkan data. Sekumpulan data yang digunakan dalam machine learning disebut DATASET, yang kemudian dibagi/di-split menjadi training dataset dan test dataset.
TRAINING DATASET digunakan untuk membuat/melatih model machine learning, sedangkan TEST DATASET digunakan untuk menguji performa/akurasi dari model yang telah dilatih/di-training.
Teknik atau pendekatan yang digunakan untuk membangun model disebut ALGORITHM seperti Decision Tree, K-NN, Linear Regression, Random Forest, dsb. dan output atau hasil dari proses melatih algorithm dengan suatu dataset disebut MODEL.
Umumnya dataset disajikan dalam bentuk tabel yang terdiri dari baris dan kolom. Bagian Kolom adalah FEATURE atau VARIABEL data yang dianalisa, sedangkan bagian baris adalah DATA POINT/OBSERVATION/EXAMPLE.
Hal yang menjadi target prediksi atau hal yang akan diprediksi dalam machine learning disebut LABEL/CLASS/TARGET. Dalam statistika/matematika, LABEL/CLASS/TARGET ini dinamakan dengan Dependent Variabel, dan FEATURE adalah Independent Variabel.


“Jadi lebih banyak mencoba dan praktik ya untuk tahu yang tepat dan relevannya?”
“Iya, selain itu untuk supervised learning, jika LABEL dari dataset kalian berupa numerik atau kontinu variabel seperti harga, dan jumlah penjualan, kita memilih metode REGRESI dan jika bukan numerik atau diskrit (Menggunakan financial data yang memiliki label untuk memprediksi apakah harga saham akan naik atau turun di minggu depan.) maka digunakan metode KLASIFIKASI. Untuk unsupervised learning, seperti segmentasi customer, kita menggunakan metode CLUSTERING,”
Start
Oke, Pertama- tama, kita check dimensi data kita terlebih dahulu. Aksara, silahkan load datanya dan gunakan .shape, .head(), .info(), dan .describe() untuk mengeksplorasi dataset secara berurut. Dataset ini adalah data pembeli online yang mengunjungi website dari suatu e-commerce selama setahun, yaitu 'https://dqlab-dataset.s3-ap-southeast-1.amazonaws.com/pythonTutorial/online_raw.csv'
import pandas as pd
dataset = pd.read_csv("https://dqlab-dataset.s3-ap-southeast-1.amazonaws.com/pythonTutorial/online_raw.csv")
print('Shape dataset:', dataset.shape)
print('\nLima data teratas:\n', dataset.head())
print('\nInformasi dataset:')
print(dataset.info())
print('\nStatistik deskriptif:\n', dataset.describe())
""" Output
Shape dataset: (12330, 18)
Lima data teratas:
Administrative Administrative_Duration ... Weekend Revenue
0 0.0 0.0 ... False False
1 0.0 0.0 ... False False
2 0.0 -1.0 ... False False
3 0.0 0.0 ... False False
4 0.0 0.0 ... True False
[5 rows x 18 columns]
Informasi dataset:
RangeIndex: 12330 entries, 0 to 12329
Data columns (total 18 columns):
Administrative 12316 non-null float64
Administrative_Duration 12316 non-null float64
Informational 12316 non-null float64
Informational_Duration 12316 non-null float64
ProductRelated 12316 non-null float64
ProductRelated_Duration 12316 non-null float64
BounceRates 12316 non-null float64
ExitRates 12316 non-null float64
PageValues 12330 non-null float64
SpecialDay 12330 non-null float64
Month 12330 non-null object
OperatingSystems 12330 non-null int64
Browser 12330 non-null int64
Region 12330 non-null int64
TrafficType 12330 non-null int64
VisitorType 12330 non-null object
Weekend 12330 non-null bool
Revenue 12330 non-null bool
dtypes: bool(2), float64(10), int64(4), object(2)
memory usage: 1.5+ MB
None
Statistik deskriptif:
Administrative Administrative_Duration ... Region TrafficType
count 12316.000000 12316.000000 ... 12330.000000 12330.000000
mean 2.317798 80.906176 ... 3.147364 4.069586
std 3.322754 176.860432 ... 2.401591 4.025169
min 0.000000 -1.000000 ... 1.000000 1.000000
25% 0.000000 0.000000 ... 1.000000 2.000000
50% 1.000000 8.000000 ... 3.000000 2.000000
75% 4.000000 93.500000 ... 4.000000 4.000000
max 27.000000 3398.750000 ... 9.000000 20.000000
[8 rows x 14 columns]
"""
Distribusi label dari dataset tidak seimbang karena total data point dengan label 1 adalah 10422 dan total data point dengan label 0 adalah 1908.
- ExitRates dan BounceRates
- Revenue dan PageValues
- TrafficType dan Weekend
dataset_corr = dataset.corr()
print('Korelasi dataset:\n', dataset.corr())
print('Distribusi Label (Revenue):\n', dataset['Revenue'].value_counts())
# Tugas praktek
print('\nKorelasi BounceRates-ExitRates:', dataset_corr.loc['BounceRates', 'ExitRates'])
print('\nKorelasi Revenue-PageValues:', dataset_corr.loc['Revenue', 'PageValues'])
print('\nKorelasi TrafficType-Weekend:', dataset_corr.loc['TrafficType', 'Weekend'])
""" Output
Korelasi dataset:
Administrative ... Revenue
Administrative 1.000000 ... 0.138631
Administrative_Duration 0.601466 ... 0.093395
Informational 0.376782 ... 0.095085
Informational_Duration 0.255757 ... 0.070250
ProductRelated 0.430832 ... 0.158280
ProductRelated_Duration 0.373647 ... 0.152130
BounceRates -0.223474 ... -0.150621
ExitRates -0.316192 ... -0.206886
PageValues 0.098771 ... 0.492569
SpecialDay -0.095054 ... -0.082305
OperatingSystems -0.006459 ... -0.014668
Browser -0.025243 ... 0.023984
Region -0.005680 ... -0.011595
TrafficType -0.033748 ... -0.005113
Weekend 0.026404 ... 0.029295
Revenue 0.138631 ... 1.000000
[16 rows x 16 columns]
Distribusi Label (Revenue):
False 10422
True 1908
Name: Revenue, dtype: int64
Korelasi BounceRates-ExitRates: 0.9134364214595573
Korelasi Revenue-PageValues: 0.49256929525120724
Korelasi TrafficType-Weekend: -0.0022212292430311273
"""Selain dengan statistik, kita juga bisa melakukan eksplorasi data dalam bentuk visual. Dengan visualisasi kita dapat dengan mudah dan cepat dalam memahami data, bahkan dapat memberikan pemahaman yang lebih baik terkait hubungan setiap variabel/ features.
Misalnya kita ingin melihat distribusi label dalam bentuk visual, dan jumlah pembelian saat weekend. Kita dapat memanfaatkan matplotlib library untuk membuat chart yang menampilkan perbandingan jumlah yang membeli (1) dan tidak membeli (0), serta perbandingan jumlah pembelian saat weekend
import matplotlib.pyplot as plt
import seaborn as sns
# checking the Distribution of customers on Revenue
plt.rcParams['figure.figsize'] = (12,5)
plt.subplot(1, 2, 1)
sns.countplot(dataset['Revenue'], palette = 'pastel')
plt.title('Buy or Not', fontsize = 20)
plt.xlabel('Revenue or not', fontsize = 14)
plt.ylabel('count', fontsize = 14)
# checking the Distribution of customers on Weekend
plt.subplot(1, 2, 2)
sns.countplot(dataset['Weekend'], palette = 'inferno')
plt.title('Purchase on Weekends', fontsize = 20)
plt.xlabel('Weekend or not', fontsize = 14)
plt.ylabel('count', fontsize = 14)
plt.show()

#checking missing value for each feature
print('Checking missing value for each feature:')
print(dataset.isnull().sum())
#Counting total missing value
print('\nCounting total missing value:')
print(dataset.isnull().sum().sum())
""" Output
Checking missing value for each feature:
Administrative 14
Administrative_Duration 14
Informational 14
Informational_Duration 14
ProductRelated 14
ProductRelated_Duration 14
BounceRates 14
ExitRates 14
PageValues 0
SpecialDay 0
Month 0
OperatingSystems 0
Browser 0
Region 0
TrafficType 0
VisitorType 0
Weekend 0
Revenue 0
dtype: int64
Counting total missing value:
112
"""
#Drop rows with missing value
dataset_clean = dataset.dropna()
print('Ukuran dataset_clean:', dataset_clean.shape)
""" Output
Ukuran dataset_clean: (12330, 18)
"""
print("Before imputation:")
# Checking missing value for each feature
print(dataset.isnull().sum())
# Counting total missing value
print(dataset.isnull().sum().sum())
print("\nAfter imputation:")
# Fill missing value with mean of feature value
dataset.fillna(dataset.mean(), inplace = True)
# Checking missing value for each feature
print(dataset.isnull().sum())
# Counting total missing value
print(dataset.isnull().sum().sum())
""" Output
Before imputation:
Administrative 14
Administrative_Duration 14
Informational 14
Informational_Duration 14
ProductRelated 14
ProductRelated_Duration 14
BounceRates 14
ExitRates 14
PageValues 0
SpecialDay 0
Month 0
OperatingSystems 0
Browser 0
Region 0
TrafficType 0
VisitorType 0
Weekend 0
Revenue 0
dtype: int64
112
After imputation:
Administrative 0
Administrative_Duration 0
Informational 0
Informational_Duration 0
ProductRelated 0
ProductRelated_Duration 0
BounceRates 0
ExitRates 0
PageValues 0
SpecialDay 0
Month 0
OperatingSystems 0
Browser 0
Region 0
TrafficType 0
VisitorType 0
Weekend 0
Revenue 0
dtype: int64
0
"""

dengan rumus ini, nilai max data akan menjadi 1 dan nilai min menjadi 0; dan nilai lainnya berada di rentang keduanya. Rumus ini tidak memungkinkan adanya rentang nilai selain 0 – 1
- Import MinMaxScaler dari sklearn.preprocessing
- Deklarasikan fungsi MinMaxScaler() ke dalam variabel scaler
- List semua feature yang akan di-scaling dan beri nama scaling_column yaitu : ['Administrative', 'Administrative_Duration', 'Informational', 'Informational_Duration', 'ProductRelated', 'ProductRelated_Duration', 'BounceRates', 'ExitRates', 'PageValues']
- Berdasarkan contoh code yang dipraktekkan oleh Aksara, ganti dataset.columns dengan scaling_column.
from sklearn.preprocessing import MinMaxScaler
#Define MinMaxScaler as scaler
scaler = MinMaxScaler()
#list all the feature that need to be scaled
scaling_column = ['Administrative','Administrative_Duration','Informational','Informational_Duration','ProductRelated','ProductRelated_Duration','BounceRates','ExitRates','PageValues']
#Apply fit_transfrom to scale selected feature
dataset[scaling_column] = scaler.fit_transform(dataset[scaling_column])
#Cheking min and max value of the scaling_column
print(dataset[scaling_column].describe().T[['min','max']])
""" Output
min max
Administrative 0.0 1.0
Administrative_Duration 0.0 1.0
Informational 0.0 1.0
Informational_Duration 0.0 1.0
ProductRelated 0.0 1.0
ProductRelated_Duration 0.0 1.0
BounceRates 0.0 1.0
ExitRates 0.0 1.0
PageValues 0.0 1.0
"""Data Pre-processing: Konversi string ke numerik
Kita memiliki dua kolom yang bertipe object yang dinyatakan dalam tipe data str, yaitu kolom 'Month' dan 'VisitorType'. Karena setiap algoritma machine learning bekerja dengan menggunakan nilai numeris, maka kita perlu mengubah kolom dengan tipe pandas object atau str ini ke bertipe numeris. Untuk itu, kita list terlebih dahulu apa saja label unik di kedua kolom ini.
Label unik kolom 'Month':
dan label unik kolom 'VisitorType':
Ok, kita dapat menggunakan LabelEncoder dari sklearn.preprocessing untuk merubah kedua kolom ini seperti ini
import numpy as np
from sklearn.preprocessing import LabelEncoder
# Convert feature/column 'Month'
LE = LabelEncoder()
dataset['Month'] = LE.fit_transform(dataset['Month'])
print(LE.classes_)
print(np.sort(dataset['Month'].unique()))
print('')
# Convert feature/column 'VisitorType'
LE = LabelEncoder()
dataset['VisitorType'] = LE.fit_transform(dataset['VisitorType'])
print(LE.classes_)
print(np.sort(dataset['VisitorType'].unique()))
""" Output
['Aug' 'Dec' 'Feb' 'Jul' 'June' 'Mar' 'May' 'Nov' 'Oct' 'Sep']
[0 1 2 3 4 5 6 7 8 9]
['New_Visitor' 'Other' 'Returning_Visitor']
[0 1 2]
"""
Bisa dilihat, bahwa LabelEncoder akan mengurutkan label secara otomatis secara alfabetik, posisi/indeks dari setiap label ini digunakan sebagai nilai numeris konversi pandas objek ke numeris (dalam hal ini tipe data int). Dengan demikian kita telah membuat dataset kita menjadi dataset bernilai numeris seluruhnya yang siap digunakan untuk pemodelan dengan algoritma machine learning tertentu.
Library Scikit-learn adalah library untuk machine learning bagi para pengguna python yang memungkinkan kita melakukan berbagai pekerjaan dalam Data Science, seperti regresi (regression), klasifikasi (classification), pengelompokkan/penggugusan (clustering), data preprocessing, dimensionality reduction, dan model selection (pembandingan, validasi, dan pemilihan parameter maupun model). Ada beberapa library machine learning di Python seperti Keras, tetapi Scikit - Learn adalah yang paling basic sehingga jika kita menguasai scikit-learn, kita dapat dengan mudah mempelajari library machine learning yang lain.
Features & Label
Dalam dataset user online purchase, label target sudah diketahui, yaitu kolom Revenue yang bernilai 1 untuk user yang membeli dan 0 untuk yang tidak membeli, sehingga pemodelan yang dilakukan ini adalah klasifikasi. Nah, untuk melatih dataset menggunakan Scikit-Learn library, dataset perlu dipisahkan ke dalam Features dan Label/Target. Variabel Feature akan terdiri dari variabel yang dideklarasikan sebagai X dan [Revenue] adalah variabel Target yang dideklarasikan sebagai y. Gunakan fungsi drop() untuk menghapus kolom [Revenue] dari dataset.
# removing the target column Revenue from dataset and assigning to X
X = dataset.drop(['Revenue'], axis = 1)
# assigning the target column Revenue to y
y = dataset['Revenue']
# checking the shapes
print("Shape of X:", X.shape)
print("Shape of y:", y.shape)
""" Output
Shape of X: (12330, 17)
Shape of y: (12330,)
"""
Sebelum kita melatih model dengan suatu algorithm machine , seperti yang saya jelaskan sebelumnya, dataset perlu kita bagi ke dalam training dataset dan test dataset dengan perbandingan 80:20. 80% digunakan untuk training dan 20% untuk proses testing.
Perbandingan lain yang biasanya digunakan adalah 75:25. Hal penting yang perlu diketahui adalah scikit-learn tidak dapat memproses dataframe dan hanya mengakomodasi format data tipe Array. Tetapi kalian tidak perlu khawatir, fungsi train_test_split( ) dari Scikit-Learn, otomatis mengubah dataset dari dataframe ke dalam format array. Apakah kamu paham.
Fungsi Training adalah melatih model untuk mengenali pola dalam data, sedangkan testing berfungsi untuk memastikan bahwa model yang telah dilatih tersebut mampu dengan baik memprediksi label dari new observation dan belum dipelajari oleh model sebelumnya.
Silahkan bagi dataset ke dalam Training dan Testing dengan melanjutkan coding yang sudah kukerjakan ini. Gunakan test_size = 0.2 dan tambahkan argumen random_state = 0, pada fungsi train_test_split( ).
from sklearn.model_selection import train_test_split
# splitting the X, and y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# checking the shapes
print("Shape of X_train :", X_train.shape)
print("Shape of y_train :", y_train.shape)
print("Shape of X_test :", X_test.shape)
print("Shape of y_test :", y_test.shape)
""" Output
Shape of X_train : (9864, 17)
Shape of y_train : (9864,)
Shape of X_test : (2466, 17)
Shape of y_test : (2466,)
"""
Training Model: Fit
Sekarang saatnya kita melatih model atau training. Dengan Scikit-Learn, proses ini menjadi sangat sederhana. Kita cukup memanggil nama algorithm yang akan kita gunakan, biasanya disebut classifier untuk problem klasifikasi, dan regressor untuk problem regresi.
sebagai contoh, kita akan menggunakan Decision Tree. Kita hanya perlu memanggil fungsi DecisionTreeClassifier() yang kita namakan “model”. Kemudian menggunakan fungsi .fit() dan X_train, y_train untuk melatih classifier tersebut dengan training dataset.
Setelah model/classifier terbentuk, selanjutnya kita menggunakan model ini untuk memprediksi LABEL dari testing dataset (X_test), menggunakan fungsi .predict(). Fungsi ini akan mengembalikan hasil prediksi untuk setiap data point dari X_test dalam bentuk array. Proses ini kita kenal dengan TESTING.
from sklearn.tree import DecisionTreeClassifier
# Call the classifier
model = DecisionTreeClassifier()
# Fit the classifier to the training data
model = model.fit(X_train,y_train)
# Apply the classifier/model to the test data
y_pred = model.predict(X_test)
print(y_pred.shape)
Kita bisa munculkan dengan fungsi .score( ). Tetapi, di banyak real problem, accuracy saja tidaklah cukup. Metode lain yang digunakan adalah dengan Confusion Matrix. Confusion Matrix merepresentasikan perbandingan prediksi dan real LABEL dari test dataset yang dihasilkan oleh algoritma ML.
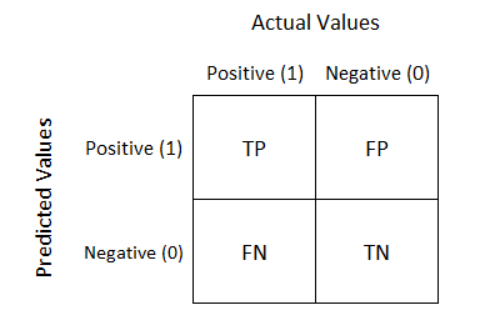
True Positive (TP): Jika user diprediksi (Positif) membeli ([Revenue] = 1]), dan memang benar(True) membeli.
True Negative (TN): Jika user diprediksi tidak (Negatif) membeli dan aktualnya user tersebut memang (True) membeli.
False Positive (FP): Jika user diprediksi Positif membeli, tetapi ternyata tidak membeli (False).
False Negatif (FN): Jika user diprediksi tidak membeli (Negatif), tetapi ternyata sebenarnya membeli.
Untuk menampilkan confusion matrix cukup menggunakan fungsi confusion_matrix() dari Scikit-Learn
from sklearn.metrics import confusion_matrix, classification_report
# evaluating the model
print('Training Accuracy :', model.score(X_train, y_train))
print('Testing Accuracy :', model.score(X_test, y_test))
# confusion matrix
print('\nConfusion matrix:')
cm = confussion_matrix(y_test, y_pred)
print(cm)
# classification report
print('\nClassification report:')
cr = classification.report(y_test, y_pred)
print(cr)
""" Output
Confusion matrix:
[[1883 161]
[188 234]]
Classification report:
precision recall fi-score support
False 0.91 0.92 0.92 2044
True 0.59 0.55 0.57 422
avg/total 0.86 0.86 0.86 2466
Pakai Metrik yang Mana?
Jika dataset memiliki jumlah data False Negatif dan False Positif yang seimbang (Symmetric), maka bisa gunakan Accuracy, tetapi jika tidak seimbang, maka sebaiknya menggunakan F1-Score.
Dalam suatu problem, jika lebih memilih False Positif lebih baik terjadi daripada False Negatif, misalnya: Dalam kasus Fraud/Scam, kecenderungan model mendeteksi transaksi sebagai fraud walaupun kenyataannya bukan, dianggap lebih baik, daripada transaksi tersebut tidak terdeteksi sebagai fraud tetapi ternyata fraud. Untuk problem ini sebaiknya menggunakan Recall.
Sebaliknya, jika lebih menginginkan terjadinya True Negatif dan sangat tidak menginginkan terjadinya False Positif, sebaiknya menggunakan Precision.
Contohnya adalah pada kasus klasifikasi email SPAM atau tidak. Banyak orang lebih memilih jika email yang sebenarnya SPAM namun diprediksi tidak SPAM (sehingga tetap ada pada kotak masuk email kita), daripada email yang sebenarnya bukan SPAM tapi diprediksi SPAM (sehingga tidak ada pada kotak masuk email).
Machine Learning Algorithm.
Sebagai dasar, akan dipelajari beberapa algorithm machine learning yaitu Logistic Regression, dan Decision Tree untuk classification problem, dan Linear regression untuk regression problem.
Classification - Logistic Regression
Logistic Regression merupakan salah satu algoritma klasifikasi dasar yang cukup popular. Secara sederhana, Logistic regression hampir serupa dengan linear regression tetapi linear regression digunakan untuk Label atau Target Variable yang berupa numerik atau continuous value, sedangkan Logistic regression digunakan untuk Label atau Target yang berupa categorical/discrete value.
Contoh continuous value adalah harga rumah, harga saham, suhu, dsb; dan contoh dari categorical value adalah prediksi SPAM or NOT SPAM (1 dan 0) atau prediksi customer SUBSCRIBE atau UNSUBSCRIBED (1 dan 0).
Umumnya Logistic Regression dipakai untuk binary classification (1/0; Yes/No; True/False) problem, tetapi beberapa data scientist juga menggunakannya untuk multiclass classification problem. Logistic regression adalah salah satu linear classifier, oleh karena itu, Logistik regression juga menggunakan rumus atau fungsi yang sama seperti linear regression yaitu:
![]()
yang disebut Logit, dimana Variabel 𝑏₀, 𝑏₁, …, 𝑏ᵣ adalah koefisien regresi, dan 𝑥₁, …, 𝑥ᵣ adalah explanatory variable/variabel input atau feature.
Output dari Logistic Regression adalah 1 atau 0; sehingga real value dari fungsi logit ini perlu ditransfer ke nilai di antara 1 dan 0 dengan menggunakan fungsi sigmoid.

Jadi, jika output dari fungsi sigmoid bernilai lebih dari 0.5, maka data point diklasifikasi ke dalam label/class: 1 atau YES; dan kurang dari 0.5, akan diklasifikasikan ke dalam label/class: 0 atau NO.
|
Logistic Regression hanya dapat mengolah data dengan tipe numerik. Pada saat preparasi data, pastikan untuk mengecek tipe variabel yang ada dalam dataset dan pastikan semuanya adalah numerik, lakukan data transformasi jika diperlukan. |
Pemodelan Permasalahan Klasifikasi dengan Logistic Regression
Pemodelan Logistic Regression dengan memanfaatkan Scikit-Learn sangatlah mudah. Dengan menggunakan dataset yang sama yaitu online_raw, dan setelah dataset dibagi ke dalam Training Set dan Test Set, cukup menggunakan modul linear_model dari Scikit-learn, dan memanggil fungsi LogisticRegression() yang diberi nama logreg.
Kemudian, model yang sudah ditraining ini bisa digunakan untuk memprediksi output/label dari test dataset sekaligus mengevaluasi model performance dengan fungsi score(), confusion_matrix() dan classification_report().
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# Call the classifier
logreg = LogisticRegression()
# Fit the classifier to the training data
logreg = logreg.fit(X_train,y_train)
#Training Model: Predict
y_pred = logreg.predict(X_test)
#Evaluate Model Performance
print('Training Accuracy :', model.score(X_train, y_train))
print('Testing Accuracy :', model.score(X_test, y_test))
# confusion matrix
print('\nConfusion matrix')
cm = confusion_matrix(y_test, y_pred)
print(cm)
# classification report
print('\nClassification report')
cr = classification_report(y_test, y_pred)
print(cr)
""" Output
Training Accuracy : 1.0
Testing Accuracy : 0.8600973236009732
Confusion matrix
[[2009 35]
[ 318 104]]
Classification report
precision recall f1-score support
False 0.86 0.98 0.92 2044
True 0.75 0.25 0.37 422
avg / total 0.84 0.86 0.83 2466
Modul R
Chapter
Progress
"""
Classification - Decision Tree
Decision Tree merupakan salah satu metode klasifikasi yang populer dan banyak diimplementasikan serta mudah diinterpretasi. Decision tree adalah model prediksi dengan struktur pohon atau struktur berhierarki. Decision Tree dapat digunakan untuk classification problem dan regression problem. Secara sederhana, struktur dari decision tree adalah sebagai berikut:

Decision tree terdiri dari :
- Decision Node yang merupakan feature/input variabel;
- Branch yang ditunjukkan oleh garis hitam berpanah, yang adalah rule/aturan keputusan, dan
- Leaf yang merupakan output/hasil.
Decision Node paling atas dalam decision tree dikenal sebagai akar keputusan, atau feature utama yang menjadi asal mula percabangan. Jadi, decision tree membagi data ke dalam kelompok atau kelas berdasarkan feature/variable input, yang dimulai dari node paling atas (akar), dan terus bercabang ke bawah sampai dicapai cabang akhir atau leaf.
Misalnya ingin memprediksi apakah seseorang yang mengajukan aplikasi kredit/pinjaman, layak untuk mendapat pinjaman tersebut atau tidak. Dengan menggunakan decision tree, dapat membreak-down kriteria-kriteria pengajuan pinjaman ke dalam hierarki seperti gambar berikut :

Seumpama, orang yang mengajukan berumur lebih dari 40 tahun, dan memiliki rumah, maka aplikasi kreditnya dapat diluluskan, sedangkan jika tidak, maka perlu dicek penghasilan orang tersebut. Jika kurang dari 5000, maka permohonan kreditnya akan ditolak. Dan jika usia kurang dari 40 tahun, maka selanjutnya dicek jenjang pendidikannya, apakah universitas atau secondary. Nah, percabangan ini masih bisa berlanjut hingga dicapai percabangan akhir/leaf node.
Seperti yang sudah dilakukan dalam prosedur pemodelan machine learning, selanjutnya dapat dengan mudah melakukan pemodelan decision tree dengan menggunakan scikit-learn module, yaitu DecisionTreeClassifier.
Latihan! Dengan menggunakan dataset online_raw.csv dan diasumsikan sudah melakukan EDA dan pre-processing, aku akan membuat model machine learning dengan menggunakan decision tree :
- Import DecisionTreeClassifier dan panggil fungsi tersebut dengan nama decision_tree
- Split dataset ke dalam training & testing dataset dengan perbandingan 70:30, dengan random_state = 0
- Latih model dengan training feature (X_train) dan training target (y_train) menggunakan .fit()
- Evaluasi hasil model decision_tree yang sudah dilatih dengan testing feature (X_test) dan print nilai akurasi dari training dan testing dengan fungsi .score()
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# splitting the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# Call the classifier
decision_tree = DecisionTreeClassifier()
# Fit the classifier to the training data
decision_tree = decision_tree.fit(X_train,y_train)
# evaluating the decision_tree performance
print('Training Accuracy :', decision_tree.score(X_train, y_train))
print('Testing Accuracy :', decision_tree.score(X_test, y_test))
""" Output
Training Accuracy : 1.0
Testing Accuracy : 0.8605028386050284
"""
Regression: Linear Regression - Part 1
Regression merupakan metode statistik dan machine learning yang paling banyak digunakan. Seperti yang dijelaskan sebelumnya, regresi digunakan untuk memprediksi output label yang berbentuk numerik atau continuous value. Dalam proses training, model regresi akan menggunakan variabel input (features) dan variabel output (label) untuk mempelajari bagaimana hubungan/pola dari variabel input dan output.

Model regresi terdiri atas 2 tipe yaitu :
- Simple regression model → model regresi paling sederhana, hanya terdiri dari satu feature (univariate) dan 1 target.
- Multiple regression model → sesuai namanya, terdiri dari lebih dari satu feature (multivariate).
Adapun model regresi yang paling umum digunakan adalah Linear Regression.
Linear regression digunakan untuk menganalisis hubungan linear antara dependent variabel (feature) dan independent variabel (label). Hubungan linear disini berarti bahwa jika nilai dari independen variabel mengalami perubahan baik itu naik atau turun, maka nilai dari dependen variabel juga mengalami perubahan (naik atau turun). Rumus matematis dari Linear Regression adalah:
![]()
untuk simple linear regression, atau
![]()
untuk multiple linear regression dengan, y adalah target/label, X adalah feature, dan a,b adalah model parameter (intercept dan slope).

Perlu diketahui bahwa tidak semua problem dapat diselesaikan dengan linear regression. Untuk pemodelan dengan linear regression, terdapat beberapa asumsi yang harus dipenuhi, yaitu :
- Terdapat hubungan linear antara variabel input (feature) dan variabel output(label). Untuk melihat hubungan linear feature dan label, dapat menggunakan chart seperti scatter chart. Untuk mengetahui hubungan dari variabel umumnya dilakukan pada tahap eksplorasi data.
- Tidak ada multicollinearity antara features. Multicollinearity artinya terdapat dependency antara feature, misalnya saja hanya bisa mengetahui nilai feature B jika nilai feature A sudah diketahui.
- Tidak ada autocorrelation dalam data, contohnya pada time-series data.
Pemodelan Linear regression menggunakan scikit-learn tidaklah sulit. Secara prosedur serupa dengan pemodelan logistic regression. Cukup memanggil LinearRegression dengan terlebih dahulu meng-import fungsi tersebut :
from sklearn.linear_model import LinearRegression
“Setelah memahami konsep dasar dari regression, kita akan berlatih membuat model machine learning dengan Linear regression. Untuk pemodelan ini kita akan menggunakan data ‘Boston Housing Dataset’. Setelah pembelajaran kamu sampai di sini, tahu tidak mengapa kita tidak bisa menggunakan data “online purchase”, Aksara?”
Pertanyaan Senja padaku terdengar seperti ujian. Aku berpikir sejenak sebelum menjawab,
“Hmm, karena untuk linear regression target/label harus berupa numerik, sedangkan target dari online purchase data adalah categorical. Apakah benar?” jawabku ragu-ragu.
Senyum Senja cukup melegakanku.
“Tepat sekali, Senja. Kalau begitu kita bisa lanjut ke pemodelan. Tujuan dari pemodelan ini adalah memprediksi harga rumah di Boston berdasarkan feature - feature yang ada. Asumsikan saja bahwa kita sudah melakukan data eksplorasi dan data pre-processing. Jadi, data yang akan digunakan adalah data yang siap untuk diproses ke tahap pemodelan.”
- Pisahkan dataset ke dalam Feature dan Label, gunakan fungsi .drop(). Pada dataset ini, label/target adalah variabel MEDV
- Checking dan print jumlah data setelah Dataset pisahkan ke dalam Feature dan Label, gunakan .shape()
- Bagi dataset ke dalam Training dan test dataset, 70% data digunakan untuk training dan 30% untuk testing, gunakan fungsi train_test_split() , dengan random_state = 0
- Checking dan print kembali jumlah data dengan fungsi .shape()
- Import LinearRegression dari sklearn.linear_model
- Deklarasikan LinearRegression regressor dengan nama reg
- Fit regressor ke training dataset dengan .fit(), dan gunakan .predict() untuk memprediksi nilai dari testing dataset.
#load dataset
import pandas as pd
housing = pd.read_csv('https://dqlab-dataset.s3-ap-southeast-1.amazonaws.com/pythonTutorial/housing_boston.csv')
#Data rescaling
from sklearn import preprocessing
data_scaler = preprocessing.MinMaxScaler(feature_range=(0,1))
housing[['RM','LSTAT','PTRATIO','MEDV']] = data_scaler.fit_transform(housing[['RM','LSTAT','PTRATIO','MEDV']])
# getting dependent and independent variables
X = housing.drop(['MEDV'], axis = 1)
y = housing['MEDV']
# checking the shapes
print('Shape of X:', X.shape)
print('Shape of y:', y.shape)
# splitting the data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# checking the shapes
print('Shape of X_train :', X_train.shape)
print('Shape of y_train :', y_train.shape)
print('Shape of X_test :', X_test.shape)
print('Shape of y_test :', y_test.shape)
##import regressor from Scikit-Learn
from sklearn.linear_model import LinearRegression
# Call the regressor
reg = LinearRegression()
# Fit the regressor to the training data
reg = reg.fit(X_train, y_train)
# Apply the regressor/model to the test data
y_pred = reg.predict(X_test)
""" Output
Shape of X: (489, 3)
Shape of y: (489,)
Shape of X_train : (342, 3)
Shape of y_train : (342,)
Shape of X_test : (147, 3)
Shape of y_test : (147,)
"""
Untuk model regression, kita menghitung selisih antara nilai aktual (y_test) dan nilai prediksi (y_pred) yang disebut error, adapun beberapa metric yang umum digunakan
Mean Squared Error (MSE) adalah rata-rata dari squared error:

Root Mean Squared Error (RMSE) adalah akar kuadrat dari MSE:

Mean Absolute Error (MAE) adalah rata-rata dari nilai absolut error:

Semakin kecil nilai MSE, RMSE, dan MAE, semakin baik pula performansi model regresi. Untuk menghitung nilai MSE, RMSE dan MAE dapat dilakukan dengan menggunakan fungsi mean_squared_error () , mean_absolute_error () dari scikit-learn.metrics dan untuk RMSE sendiri tidak terdapat fungsi khusus di scikit-learn tapi dapat dengan mudah kita hitung dengan terlebih dahulu menghitung MSE kemudian menggunakan numpy module yaitu, sqrt() untuk memperoleh nilai akar kuadrat dari MSE.
- Import library yang digunakan: mean_squared_error, mean_absolute_error dari sklearn.metrics dan numpy sebagai aliasnya yaitu np. Serta, import juga matplotlib.pyplot sebagai aliasnya, plt.
- Hitung dan print nilai MSE dan RMSE dengan menggunakan argumen y_test dan y_pred, untuk rmse gunakan np.sqrt()
- Buat scatter plot yang menggambarkan hasil prediksi (y_pred) dan harga actual (y_test)
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
import matplotlib.pyplot as plt
#Calculating MSE, lower the value better it is. 0 means perfect prediction
mse = mean_squared_error(y_test, y_pred)
print('Mean squared error of testing set:', mse)
#Calculating MAE
mae = mean_absolute_error (y_test, y_pred)
print('Mean absolute error of testing set:', mae)
#Calculating RMSE
rmse = np.sqrt(mse)
print('Root Mean Squared Error of testing set:', rmse)
#Plotting y_test dan y_pred
plt.scatter(y_test, y_pred, c = 'green')
plt.xlabel('Price Actual')
plt.ylabel('Predicted value')
plt.title('True value vs predicted value : Linear Regression')
plt.show()
"""
Unsupervised Learning adalah teknik machine learning dimana tidak terdapat label atau output yang digunakan untuk melatih model. Jadi, model dengan sendirinya akan bekerja untuk menemukan pola atau informasi dari dataset yang ada. Metode unsupervised learning yang dikenal dengan clustering. Sesuai dengan namanya, Clustering memproses data dan mengelompokkannya atau mengcluster objek/sample berdasarkan kesamaan antar objek/sampel dalam satu kluster, dan objek/sample ini cukup berbeda dengan objek/sample di kluster yang lain. Contohnya pada gambar berikut:

"Nja, mau tanya. Kita tahu dari mana bentuk polanya?”
“Pada awalnya kita tidak mengetahui bagaimana pola dari objek/sample, termasuk juga tidak mengetahui bagaimana kesamaan maupun perbedaan antara objek yang satu dengan objek yang lain. Setelah dilakukan clustering, baru dapat terlihat bawah objek/sample tersebut dapat dikelompokkan ke dalam 3 kluster. Untuk menjelaskan tentang metode Clustering, kita akan menggunakan metode clustering yang sangat populer, yaitu K-Means Algorithm yang akan kita praktikkan nanti.”
K-Means Clustering
"Jadi, Algorithm K-Means itu apa dan bagaimana cara kerjanya?” tanyaku antusias.
“K-Means merupakan tipe clustering dengan centroid based (titik pusat). Artinya kesamaan dari objek/sampel dihitung dari seberapa dekat objek itu dengan centroid atau titik pusat.”
Aku masih penasaran. “Jadi, bagaimana kita mengukur kedekatan objek dan centroid?”
“Untuk menghitung kedekatan, digunakan perhitungan jarak antar 2 buah data atau jarak Minkowski. Saya share yah rumusnya,” ujar Senja.
Aku menyimak isi rumus yang dibagikan Senja di slide presentasinya:
![]()
xi , xj adalah dua buah data yang akan dihitung jaraknya, dan p = dimensi/jumlah dari data
Terdapat beberapa tipe perhitungan jarak yang dapat digunakan, yaitu :
- Jarak Manhattan di mana g = 1
- Jarak Euclidean di mana g = 2
- Jarak Chebychev di mana g = ∞
“Nja, aku masih bingung, cara menentukan centroid bagaimana caranya?”
“Untuk menentukan centroid, pada awalnya kita perlu mendefinisikan jumlah centroid (K) yang diinginkan, semisalnya kita menetapkan jumlah K = 3; maka pada awal iterasi, algorithm akan secara random menentukan 3 centroid. Setelah itu, objek/sample/data point yang lain akan dikelompokkan sebagai anggota dari salah satu centroid yang terdekat, sehingga terbentuk 3 cluster data. Sampai sini cukup dipahami?”
“Yup, boleh lanjut, Nja,” sahutku mempersilakan Senja kembali menjelaskan.
“Iterasi selanjutnya, titik-titik centroid diupdate atau berpindah ke titik yang lain, dan jarak dari data point yang lain ke centroid yang baru dihitung kembali, kemudian dikelompokkan kembali berdasarkan jarak terdekat ke centroid yang baru. Iterasi akan terus berlanjut hingga diperoleh cluster dengan error terkecil, dan posisi centroid tidak lagi berubah.”

“Secara prosedur, tahap eksplorasi data untuk memahami karakteristik data, dan tahap preprocessing tetap dilakukan. Tetapi dalam unsupervised learning, kita tidak membagi dataset ke feature dan label; dan juga ke dalam training dan test dataset, karena pada dasarnya kita tidak memiliki informasi mengenai label/target data,”
“Untuk praktik ini, kita akan menggunakan dataset ‘Mall Customer Segmentation’,” ujar Senja.
Aku membaca detail latihan yang sudah ia catatkan untukku:
Dataset ini merupakan data customer suatu mall dan berisi basic informasi customer berupa : CustomerID, age, gender, annual income, dan spending score. Adapun tujuan dari clustering adalah untuk memahami customer - customer mana saja yang sering melakukan transaksi sehingga informasi ini dapat diberikan kepada marketing team untuk membuat strategi promosi yang sesuai dengan karakteristik customer.
“Kita akan melakukan segmentasi customer, dengan memanfaatkan fungsi KMeans dari Scikit-Learn.cluster. Silakan berlatih dengan intruksi di catatan tadi ya, Aksara.”
Aku membuka kembali catatan yang berisi intruksi Senja:
- Import pandas sebagai aliasnya dan KMeans dari sklearn.cluster.
- Load dataset 'https://dqlab-dataset.s3-ap-southeast-1.amazonaws.com/pythonTutorial/mall_customers.csv' dan beri nama dataset
- Diasumsikan EDA dan preprocessing sudah dilakukan, selanjutnya kita memilih feature yang akan digunakan untuk membuat model yaitu annual_income dan spending_score. Assign dataset dengan feature yang sudah dipilih ke dalam 'X'. Pada dasarnya terdapat teknik khusus yang dilakukan untuk menyeleksi feature - feature (Feature Selection) mana saja yang dapat digunakan untuk machine learning modelling, karena tidak semua feature itu berguna. Beberapa feature justru bisa menyebabkan performansi model menurun. Tetapi untuk problem ini, secara default kita akan menggunakan annual_income dan spending_score.
- Deklarasikan KMeans( ) dengan nama cluster_model dan gunakan n_cluster = 5. n_cluster adalah argumen dari fungsi KMeans( ) yang merupakan jumlah cluster/centroid (K). random_state = 24.
- Gunakan fungsi .fit_predict( ) dari cluster_model pada 'X' untuk proses clustering.
#import library
import pandas as pd
from sklearn.cluster import KMeans
#load dataset
dataset = pd.read_csv("https://dqlab-dataset.s3-ap-southeast-1.amazonaws.com/pythonTutorial/mall_customers.csv")
#selecting features
X = dataset[['annual_income','spending_score']]
#Define KMeans as cluster_model
cluster_model = KMeans(n_clusters = 5, random_state = 24)
labels = cluster_model.fit_predict(X)
Inspect & Visualizing the Cluster
“Satu lagi, Aksara kalau sudah membuat cluster, tolong visualisasikan hasil dari clustering yang telah kamu lakukan sebelumnya ya. Langkah-langkahnya sudah saya email,” tambah Senja lagi tepat saat aku sedang membuka pesan berisi intruksi tambahan darinya:
- Pertama - tama, import matplotlib.pyplot dan beri inisial plt.
- Gunakan fungsi .values untuk mengubah tipe ‘X’ dari dataframe menjadi array
- Pisahkan X kedalam xs dan ys, di mana xs adalah Kolom index [0] dan ys adalah kolom index [1]
- Buatlah scatter plot plt.scatter() dari xs dan ys, kemudian tambahkan c = labels untuk secara otomatis memberikan warna yang berbeda pada setiap cluster, dan alpha = 0.5 ke dalam scatter plot argumen.
- Hitunglah koordinat dari centroid menggunakan .cluster_centers_ dari cluster_model, deklarasikan ke dalam variabel centroids.
- Pisahkan centroids kedalam centroids_x dan centroids_y, di mana centroids_x adalah kolom index [0] dan centroids_y adalah kolom index [1]
- Buatlah scatter plot dari centroids_x dan centroids_y , gunakan ‘D’ (diamond) sebagai marker parameter, dengan ukuran 50, s = 50
Jika dijalankan dengan ![]() akan diperoleh grafik seperti berikut ini
akan diperoleh grafik seperti berikut ini

#import library
import matplotlib.pyplot as plt
#convert dataframe to array
X = X.values
#Separate X to xs and ys --> use for chart axis
xs = X[:,0]
ys = X[:,1]
# Make a scatter plot of xs and ys, using labels to define the colors
plt.scatter(xs,ys,c=labels, alpha=0.5)
# Assign the cluster centers: centroids
centroids = cluster_model.cluster_centers_
# Assign the columns of centroids: centroids_x, centroids_y
centroids_x = centroids[:,0]
centroids_y = centroids[:,1]
# Make a scatter plot of centroids_x and centroids_y
plt.scatter(centroids_x,centroids_y,marker='D', s=50)
plt.title('K Means Clustering', fontsize = 20)
plt.xlabel('Annual Income')
plt.ylabel('Spending Score')
plt.show()
Measuring Cluster Criteria
“Segmentasinya udah jadi nih, Nja. Tapi, bagaimana kita tahu bahwa membagi segmentasi ke dalam 5 cluster adalah segmentasi yang paling optimal? Karena jika dilihat pada gambar beberapa data point masih cukup jauh jaraknya dengan centroidnya.”
“Clustering yang baik adalah cluster yang data point-nya saling rapat/sangat berdekatan satu sama lain dan cukup berjauhan dengan objek/data point di cluster yang lain. Jadi, objek dalam satu cluster tidak tersebut berjauhan. Nah, untuk mengukur kualitas dari clustering, kita bisa menggunakan inertia,” jawab Senja langsung.
Aku kembali bertanya karena rasanya masih ada yang janggal. “Memang apa fungsi inertia, Nja?”
“Inertia sendiri mengukur seberapa besar penyebaran object/data point data dalam satu cluster, semakin kecil nilai inertia maka semakin baik. Kita tidak perlu bersusah payah menghitung nilai inertia karena secara otomatis, telah dihitung oleh KMeans( ) ketika algorithm di fit ke dataset. Untuk mengecek nilai inertia cukup dengan print fungsi .inertia_ dari model yang sudah di fit ke dataset.”
“Kalau begitu, bagaimana caranya mengetahui nilai K yang paling baik dengan inertia yang paling kecil? Apakah harus trial Error dengan mencoba berbagai jumlah cluster?”
“Benar, kita perlu mencoba beberapa nilai, dan memplot nilai inertia-nya. Semakin banyak cluster maka inertia semakin kecil. Sini deh, saya tunjukkan gambarnya.”

Meskipun suatu clustering dikatakan baik jika memiliki inertia yang kecil tetapi secara praktikal in real life, terlalu banyak cluster juga tidak diinginkan. Adapun rule untuk memilih jumlah cluster yang optimal adalah dengan memilih jumlah cluster yang terletak pada “elbow” dalam intertia plot, yaitu ketika nilai inertia mulai menurun secara perlahan. Jika dilihat pada gambar maka jumlah cluster yang optimal adalah K = 3.
Untuk membuat inertia plot, silakan memanfaatkan fungsi looping (for):
- Pertama - tama, buatlah sebuah list kosong yang dinamakan 'inertia'. List ini akan kita gunakan untuk menyimpan nilai inertia dari setiap nilai K.
- Gunakan for untuk membuat looping dengan range 1-10. Sebagai index looping gunakan k
- Di dalam fungsi looping, deklarasikan KMeans() dengan nama cluster_model dan gunakan n_cluster = k, dan random_state = 24
- Gunakan fungsi .fit() dari cluster_model pada 'X'
- Dari dari cluster_model yang sudah di-fit ke dataset, dapatkan nilai inertia menggunakan inertia_ dan deklarasikan sebagai inertia_value
- Append inertia_value ke dalam list 'inertia'
- Setelah iterasi/looping selesai plotlah list 'inertia' tadi sebagai ordinat-nya dan absica-nya adalah range(1, 10).
#import library
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
#Elbow Method - Inertia plot
inertia = []
#looping the inertia calculation for each k
for k in range(1, 10):
#Assign KMeans as cluster_model
cluster_model = KMeans(n_clusters = k, random_state = 24)
#Fit cluster_model to X
cluster_model.fit(X)
#Get the inertia value
inertia_value = cluster_model.inertia_
#Append the inertia_value to inertia list
inertia.append(inertia_value)
##Inertia plot
plt.plot(range(1, 10), inertia)
plt.title('The Elbow Method - Inertia plot', fontsize = 20)
plt.xlabel('No. of Clusters')
plt.ylabel('Inertia')
plt.show()